

Part 1 of this article, published in the April issue of SA Instrumentation and Control, defined Machine Learning and discussed what makes Industrial Machine Learning different. In part 2, aspects of the practical implementation of Industrial Machine Learning are presented. Interested readers can review the full article at https://www.instrumentation.co.za/12850r.
Prerequisites for Industrial Machine Learning (IML)
IML platforms are designed to be easily configurable and to provide rapid return on investment. To unlock this value, however, there are some critical prerequisites one needs to be aware of before one can start implementing IML models. The main requirements for IML are:
• Sufficient instrumentation and data points/variables in place for the machine or process in order to build a relevant machine or process model.
• Sufficient historical data, ideally one year of data, but a minimum of six months – to ‘understand’ or ‘recognise’ the machine or process behaviour patterns.
• The ability to access the historical information to make it available to the IML platform.
IML is best utilised for:
• Critical processes where quality or yield issues only become apparent during subsequent processing and as such lead to waste.
• Critical equipment where unplanned breakdowns cause major production disruption for the whole plant.
• Equipment or processes where safety is a major concern, so preventive measures are required.
• Slow-moving processes where there is sufficient time to react in order to give feedback to the machine to take action before actual anomalies occur.
• Processes and equipment where there is adequate domain knowledge of the process or equipment.
Implementation approach
In order to ensure optimal effectiveness, the creation of accurate IML models is mostly an iterative process. Figure 1 depicts the typical high-level approach when implementing an IML model.
IML in action
To depict IML practically, let us look at an example of a large pump for which we want to detect anomalies for predictive maintenance purposes. To configure a Machine Learning (ML) model for the pump, the process engineer, or manager, will start by selecting all the tags that are relevant to the operations of the pump. These might typically include the inlet and outlet pressures, flowrate, motor speed, liquid temperature, power consumption and vibration level, depending on the available signals and installed sensors.

Once all of the relevant tags have been selected, the next step is to define the historic time period for the model to ‘train’ on. These periods should typically be six to 12 months of historic data and should be during a period where, for most of the time, the pump was in a ‘normal’ or ‘healthy’ condition. The IML uses an automated, iterative process where the model continuously adapts and tests itself, based on the historic data, to find the right combination of algorithms that are able to ‘predict’ the values with an acceptable degree of accuracy. Most IML platforms automatically define ‘normal’ operations and handle (exclude) outliers and ‘bad-quality’ data.
After the model has been trained within acceptable accuracy, the last step is to configure the production filters (i.e. only monitor when the pump is running) as well as acceptable thresholds for value deviations. The model is then ready for deployment and actively starts to collect and evaluate real-time data coming from the plant.
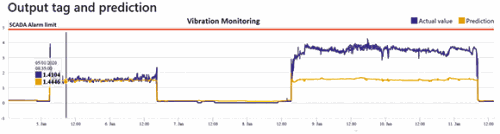
A classic way of doing predictive maintenance on large rotating equipment such as a pump is to use vibration monitoring. Figure 2 shows the actual values of the vibration monitoring coming from the pump motor in blue, with the ‘predicted’ or expected values displayed in yellow. The scada alarm limit is also shown as the orange line. One can clearly see that the IML tool picked up an anomaly in vibration even though vibration was still below the normal alarm limit.
In this scenario the pump has started to vibrate more than expected, even though the speed, flow and other parameters stayed ‘normal’. The root cause of this behaviour could be mechanical issues inside the pump, mechanical issues outside or surrounding the pump, or it could be the characteristics of fluid going through the pump that changed, to name a few.
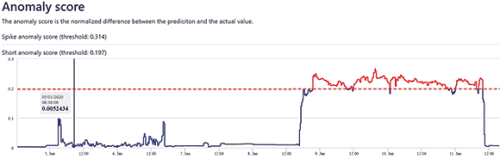
The IML model detected a significant difference between the predicted and actual values, as shown in Figure 3 and was able to alarm an anomaly for the operator who would otherwise not have been aware of the impending issue as no scada alarm was raised.
In addition, IML platforms offer drill-down capabilities where operators or engineers can view the alarmed event together with all the associated tag trends within the model, making it easy to identify the cause of the deviation and to decide if the pump needs maintenance or not.
Summary
IML technologies are now more accessible and easier to use. IML platforms are designed to integrate with the most common industrial protocols, historians and scada software to enhance and add even more value to existing systems. With unique and automated data cleaning, IML platforms automatically handle outliers and ‘bad quality’ data, which are common to industrial process data. IML is typically a ‘no-code’ platform that requires no knowledge of ML or data science. The tools are purposefully designed to be used by the people who work in the production environment today. They are built to eliminate the need for code developers, data scientists or expensive external consultants. These solutions give the people closest to the processes the necessary insights to detect anomalies before they occur, optimise production and reduce costs.
| Tel: | +27 12 349 2919 |
| Email: | [email protected] |
| www: | www.iritron.co.za |
| Articles: | More information and articles about Iritron |


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version